|
机器之心专栏 机器之心编辑部 深度学习模型架构越复杂越好吗? 自过去的几十年里,人工神经网络取得了显著的进展,这归功于一种理念:增加网络的复杂度可以提高性能。从 AlexNet 引爆了深度学习在计算机视觉的热潮后,研究者们为了提升深度网络的性能,精心地设计出了各种各样的模块,包括 ResNet 中的残差,ViT 中的注意力机制等。然而,尽管深层的复杂神经网络可以取得很好的性能,但他们在实际应用中的推理速度往往会受到这些复杂操作的影响而变慢。 来自华为诺亚、悉尼大学的研究者们提出了一种极简的神经网络模型 VanillaNet,以极简主义的设计为理念,网络中仅仅包含最简单的卷积计算,去掉了残差和注意力模块,在计算机视觉中的各种任务上都取得了不俗的效果。13 层的 VanillaNet 模型在 ImageNet 上就可以达到 83% 的精度,挑战了深度学习模型中复杂设计的必要性。
 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
极简网络的架构设计
 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
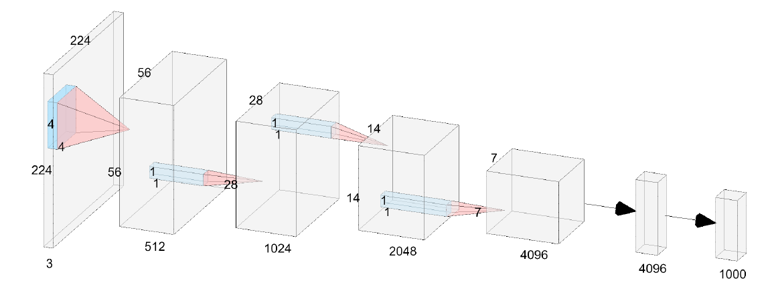
图 1. 6 层的 VanillaNet 结构示意图 图 1 展示了 6 层的 VanillaNet 的结构,它的结构十分简洁,由 5 个卷积层,5 个池化层,一个全连接层和 5 个激活函数构成,结构的设计遵循 AlexNet 和 VGG 等传统深度网络的常用方案:分辨率逐渐缩小,而通道数逐渐增大,不包含残差,自注意力等计算。 然而,如此简单的神经网络结构真的可以达到 SOTA 的精度吗?从过往的经验来看,AlexNet 和 VGG 等网络由于难以训练,精度低等特性早已被抛弃。而如何提升这类网络的精度,是一个需要解决的难关。 极简网络的训练方案 作者认为,VanillaNet 的瓶颈主要在于由于其层数少带来的非线性差的问题,作者基于此观点,首先提出了深度训练策略来解决这一问题。 针对 VanillaNet 中的一个卷积层,深度训练策略提出将其拆分为两个卷积层,从而增加其非线性,然而,将一层拆分成两层会显著增加网络的计算量和复杂度,因此,作者提出只需在训练时增加网络层数,在推理时将其融合即可。具体来说,被拆分为两层的卷积会使用如下的激活函数:
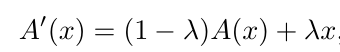 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
是由一个传统非线性激活函数(如 ReLU 等)和恒等映射加权得到。在网络训练的初始阶段,非线性激活函数会占主导地位,使得网络在开始训练时具有较高的非线性,在网络训练的过程中,恒等映射的权值会逐渐提升,此时该激活函数会逐渐变为线性的恒等映射,通过以下公式简单推导:
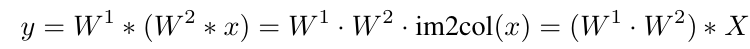 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
不具有非线性激活的两个卷积层就可以被融合为一层,从而达到了” 深层训练,浅层推理 “的效果。 此外,作者还提出了一种基于级数启发的激活函数,来进一步增加网络非线性,具体的,假设为任意现有的非线性激活函数,级数激活函数通过对激活函数进行偏置和加权,得到多个激活函数的叠加,从而使得单个激活函数具有更强的非线性:
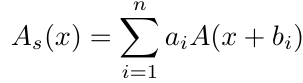 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
作者对这一形式又进行了改进,使得该激活函数可以学习到全局信息而非单个输入点的信息:
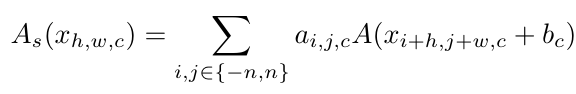 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
作者认为,可以通过提出这两个改进方案,增加网络的非线性,从而使得极简网络也具有媲美甚至超越复杂网络的精度。 极简网络的威力 为了证明 VanillaNet 的有效性,作者在计算机视觉的三大主流任务:图像分类、检测和分割上进行了实验。 作者首先验证了提出的深度训练方案和级数激活函数的有效性:
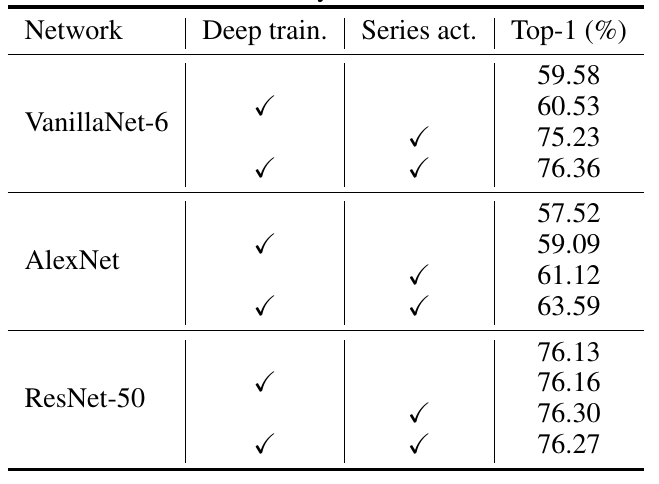 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
表 1 极简网络在图像分类的性能 从上表中可以看到,所提出的两个方案可以大幅提升 VanillaNet 的精度,在 ImageNet 上有数十个点的提升,此外,作者还在 AlexNet 这种传统网络上也进行了实验,效果提升依旧十分惊艳,这证明了简单的网络设计只要通过精心的设计和训练,仍然具有强大的威力。而对于 ResNet50 这类复杂网络来说,本文提出的设计方案收效甚微,说明这类方案对于简单的网络更为有效。
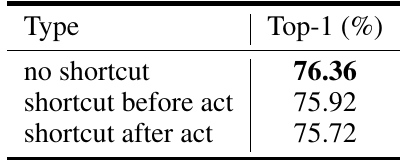 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
表 2 极简网络在图像分类的性能 残差模块在 VanillaNet 这种简单的网络中是否还奏效?作者同样针对这一问题进行了实验,实验表明,不管是采用 ResNet 本身的残差方案还是改进后的 PreAct-ResNet 残差方案,对于 VanillaNet 来说都没有提升,这是否说明了残差网络不是深度学习的唯一选择?这值得后续研究者们的思考。作者的解释是由于 VanillaNet 的深度较少,其主要瓶颈在于非线性而非残差,残差反而可能会损害网络的非线性。 接下来,作者对比了 VanillaNet 和各类经过复杂设计的网络在 ImageNet 分类任务上的精度。
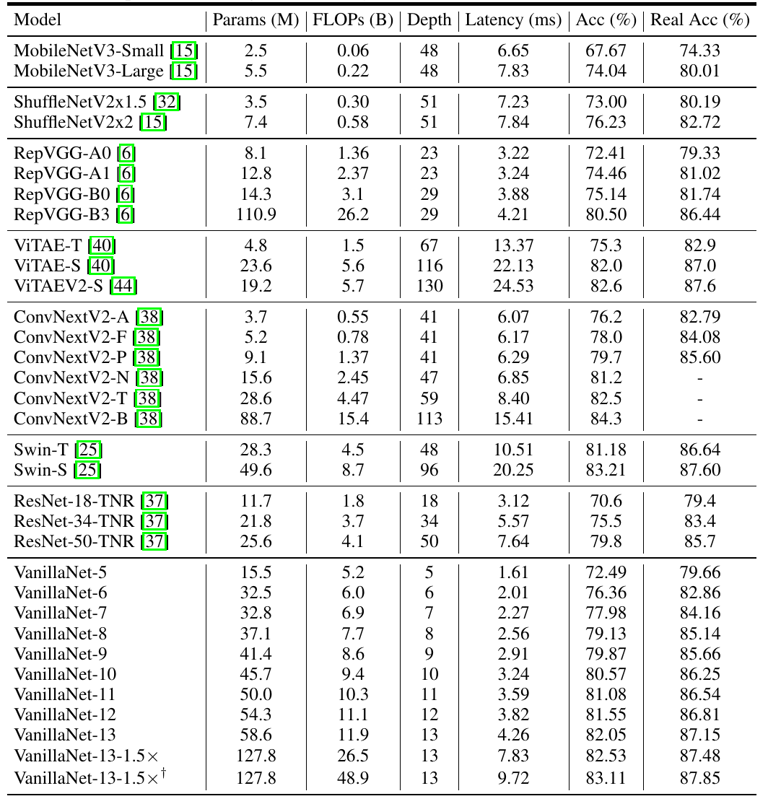 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
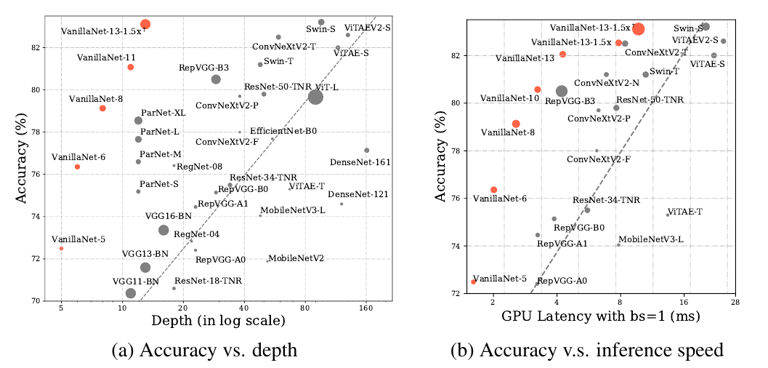
表 3 极简网络在图像分类的性能 可以看到,所提出的 VanillaNet 具有十分惊艳的速度和精度指标,例如 VanillaNet-9 仅仅使用 9 层,就在 ImageNet 上达到了接近 80% 的精度,和同精度的 ResNet-50 相比,速度提升一倍以上(2.91ms v.s. 7.64ms),而 13 层的 VanillaNet 已经可以达到 83% 的 Top-1 准确率,和相同精度的 Swin-S 网络相比速度快 1 倍以上。尽管 VanillaNet 的参数量和计算量都远高于复杂网络,但由于其极简设计带来的优势,速度反而更快。
 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
图 2 极简网络在图像分类的性能 图 2 更直观的展示了 VanillaNet 的威力,通过使用极少的层数,在 batch size 设置为 1 的情况下,VanillaNet 可以达到 SOTA 的精度和速度曲线。
 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供 13层网络拿下83%精度,华为诺亚新型神经网络架构VanillaNet「简约」到极致© 由 ZAKER 提供
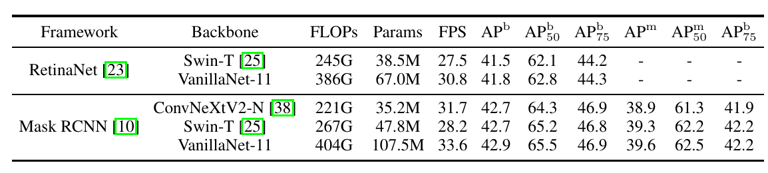
表 4 极简网络在检测和分割任务的性能 为了进一步显示 VanillaNet 在不同任务的能力,作者同样在检测和分割模型上进行了实验,实验表明,在下游任务上,VanillaNet 也可以在同精度下具有更好的 FPS,证明了 VanillaNet 在计算机视觉中的潜力。 总结来说,VanillaNet 是一种十分简洁但强大的计算机视觉网络架构,使用简单的卷积架构就可以达到 SOTA 的性能。自从 Transformer 被引入视觉领域后,注意力机制被认为是十分重要且有效的结构设计,然而 ConvNeXt 通过更好的性能重振了卷积网络的信心。那么,VanillaNet 是否可以引发无残差网络、浅层网络等设计 “文艺复兴” 的浪潮?让我们拭目以待。
| 


 雷达卡
雷达卡

 发表于 2023-5-28 09:22
发表于 2023-5-28 09:22
 照妖镜
照妖镜 楼主
楼主