|
转自超能网NVIDIA在去年9月发布了基于Ada Lovelace架构的GPU,此前GeForce RTX 4090和RTX 4080已相继上市,分别搭载的是AD102和AD103。不过对于大部分游戏玩家来说,这两款定位高端的显卡虽然性能强劲,但定价较高,并非是其首选的产品。进入2023年后,NVIDIA带来了定位更低的GeForce RTX 4070 Ti,更为贴近主流。GeForce RTX 4070 Ti规格 NVIDIA在发布Ada Lovelace架构GPU的时候就公布了三颗GPU,分别是RTX 4090所用的AD102,RTX 4080所用的AD103,以及这次RTX 4070 Ti所用的是AD104,拥有完整的5组GPC,每个含有6个TPC,共30组TPC,每组有两个SM单元,共60组。 与完整的AD104核心相比,RTX 4070 Ti上用的AD104-400少了两个NVDNC和一个NVENC,完整AD104应该是三个NVENC与三个NVDNC的,估计完整规格要在专业显卡上才会使用。 [size=1.2em]显卡规格参数对比
型号 | RTX 4070 Ti | RTX 4080 | 架构 | Ada Lovelace | Ada Lovelace | 核心代号 | AD104-400 | AD103-300 | 晶体管数目(亿) | 358 | 459 | 制程工艺 (nm) | TSMC 4N NVIDIA定制工艺 | TSMC 4N NVIDIA定制工艺 | GPCs | 5 | 7 | TPCs | 30 | 38 | SMs/CUs | 60 | 76 | CUDA Cores | 7680 | 9728 | Tensor Cores | 240(第四代) | 304(第四代) | RT Cores | 60(第三代) | 76(第三代) | 纹理单元 | 240 | 304 | 光栅单元 | 80 | 112 | Boost频率(MHz) | 2610 | 2505 | 峰值纹理填充速度 (GT/s) | 626 | 761.5 | L2缓存(kb) | 49152 | 65536 | 显存 | 12GB GDDR6X | 16GB GDDR6X | 显存位宽(bit) | 192 | 256 | 显存数据速率(Gbps) | 21 | 22.4 | 显存频率(MHz) | 10500 | 11200 | 最大显存带宽 (GB/s) | 504 | 716.8 | NVIDIA Encoder (NVENC) | 第 8 代 | 第 8 代 | NVIDIA 解码器 (NVDEC) | 第 5 代 | 第 5 代 | 显示器接口 | 3 x DisplayPort
1 x HDMI | 3 x DisplayPort
1 x HDMI | 多显示器 | 4 | 4 | HDCP | 2.3 | 2.3 | 最高 GPU 温度 (℃) | 90 | 90 | TGP (W) | 285 | 320 | 推荐电源(W) | 700 | 750 | 供电接口 | 16-Pin(含 1 个2x 8-Pin转16 针接口适配器) | 16-Pin(含 1 个3x 8-Pin转16 针接口适配器) | PCIe接口 | PCIe 4.0 x16 | PCIe 4.0 x16 | 发售时建议零售价 | 6499 RMB | 9499 RMB | 超 能 网 制 作 |
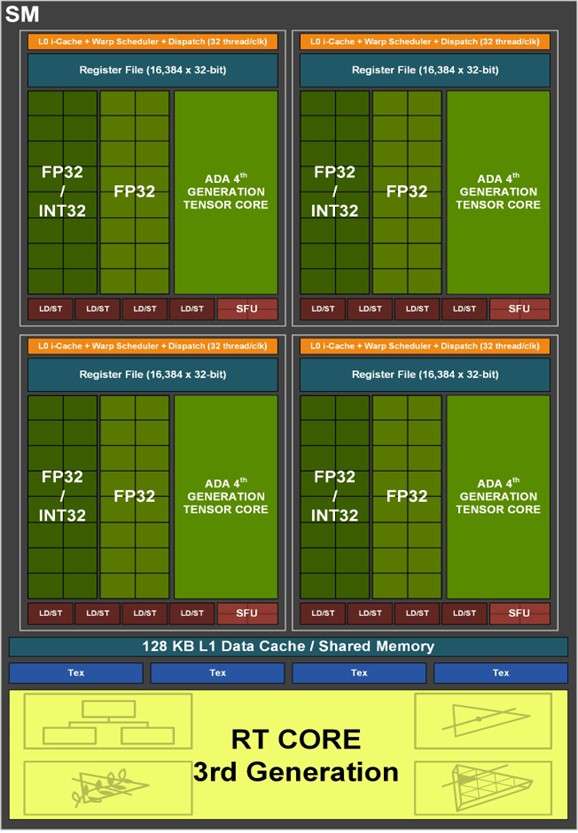
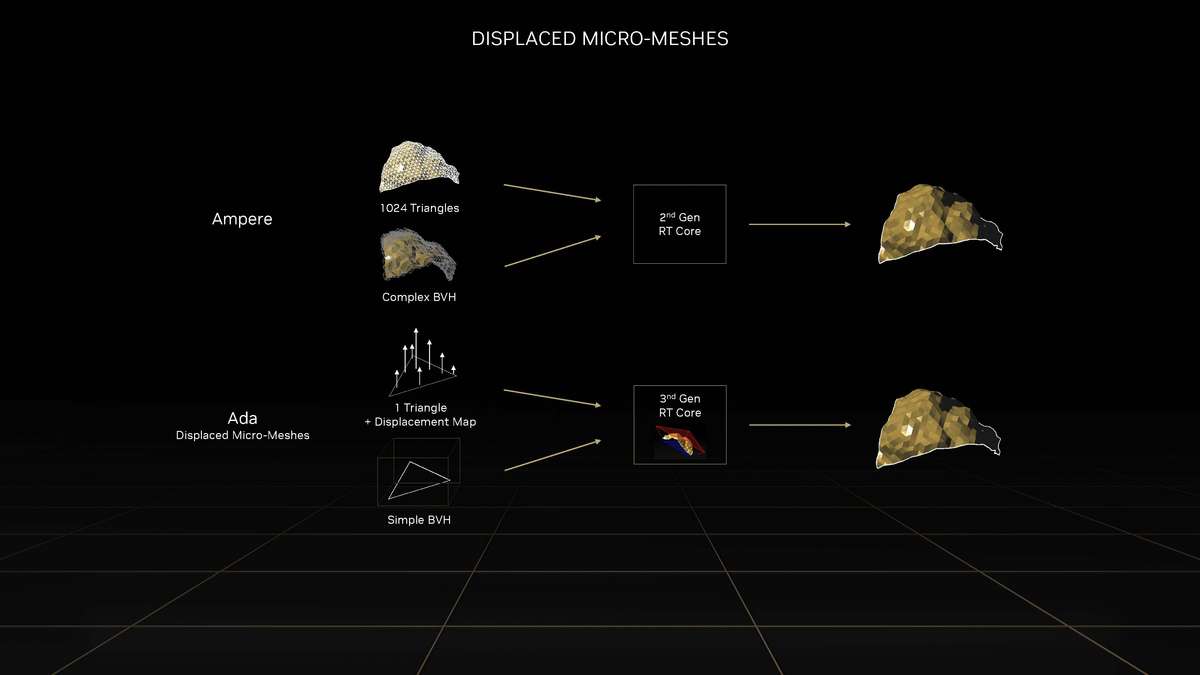
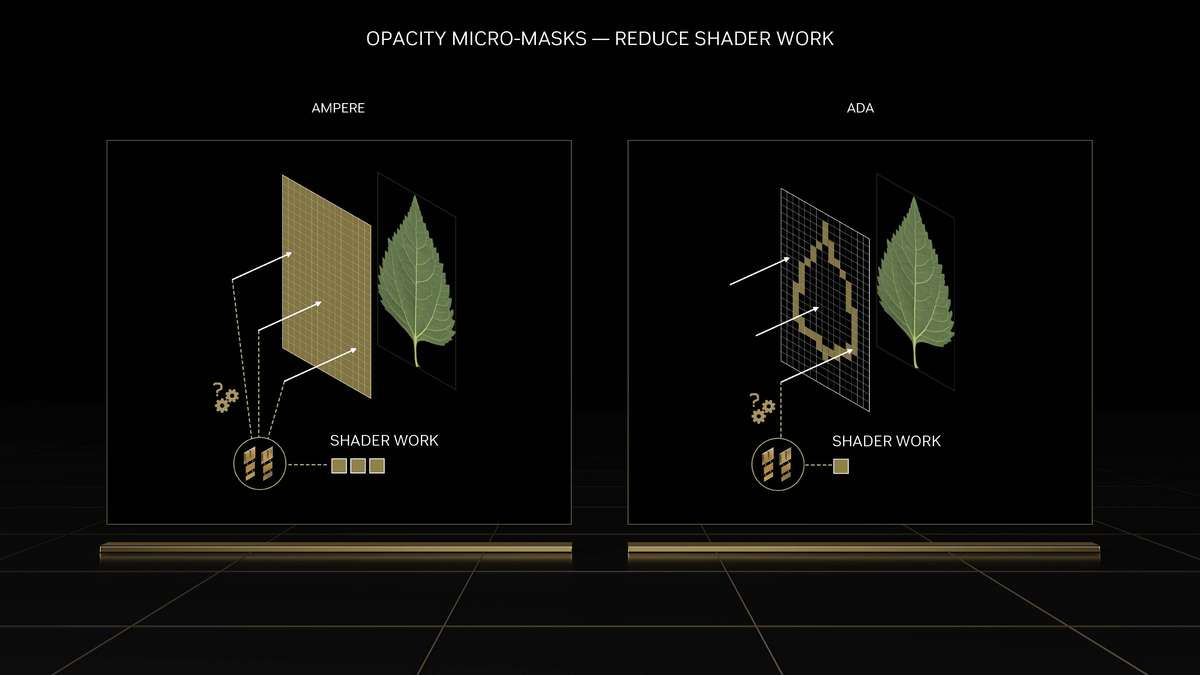
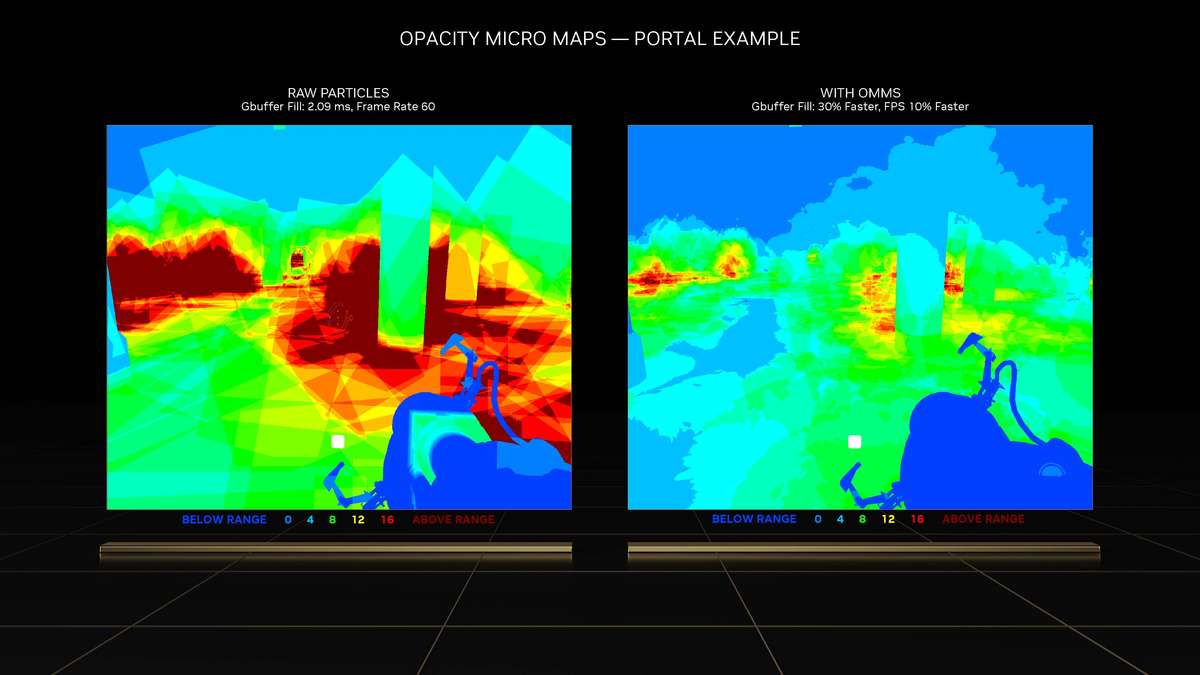
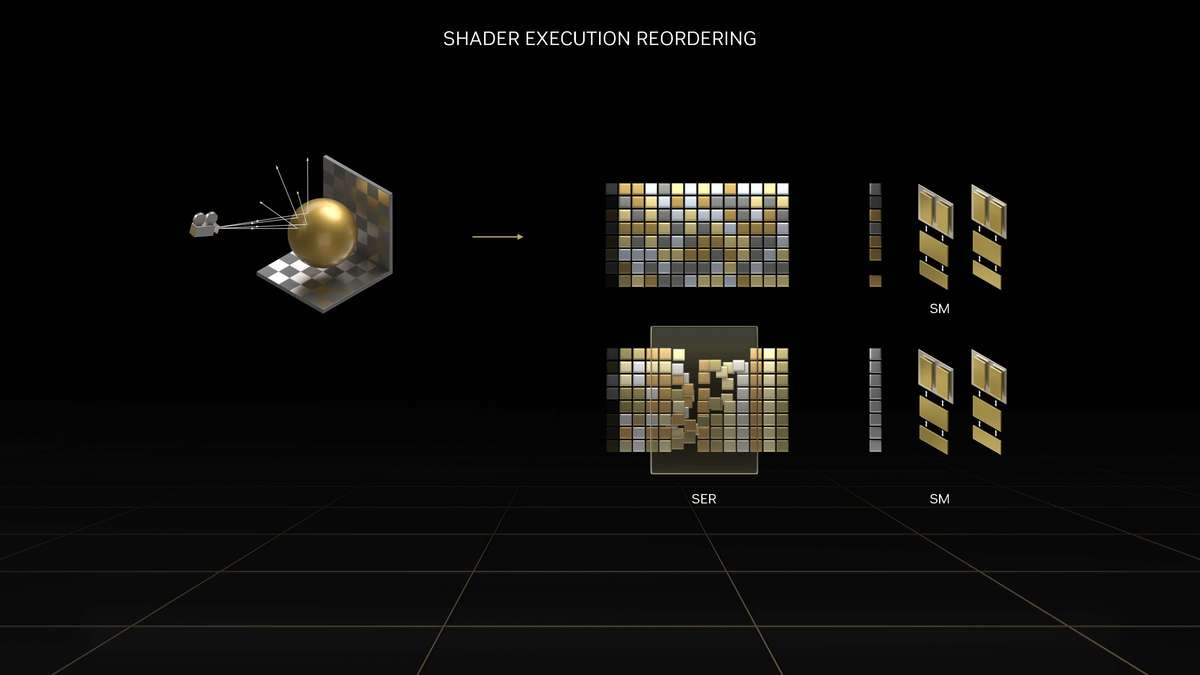
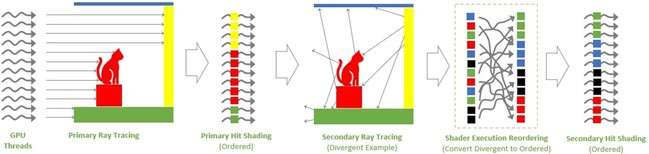
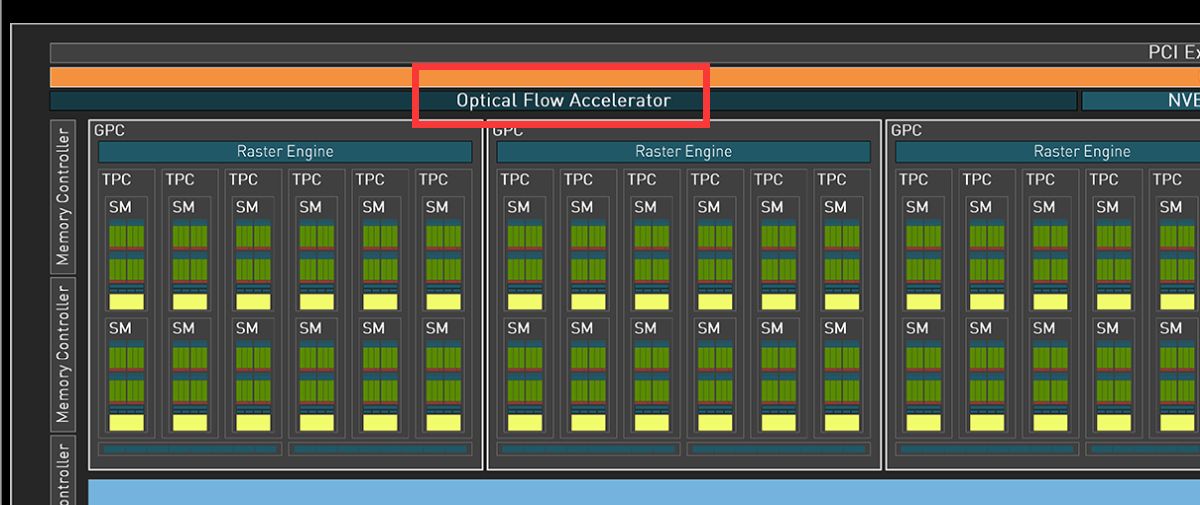
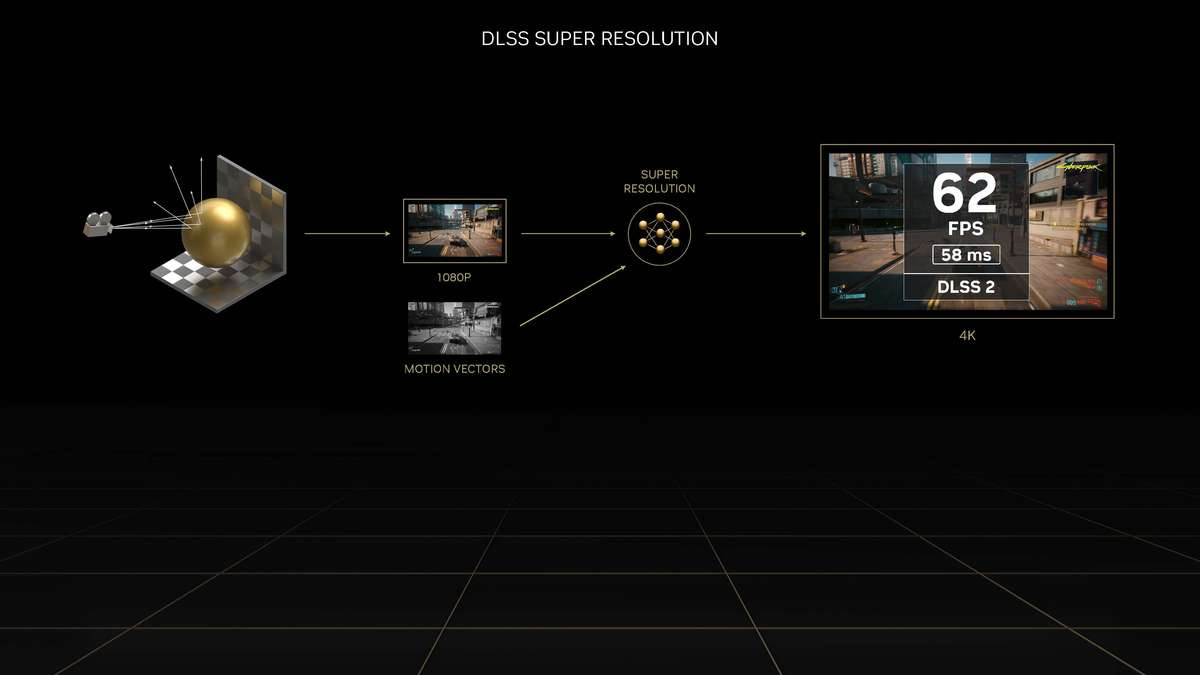
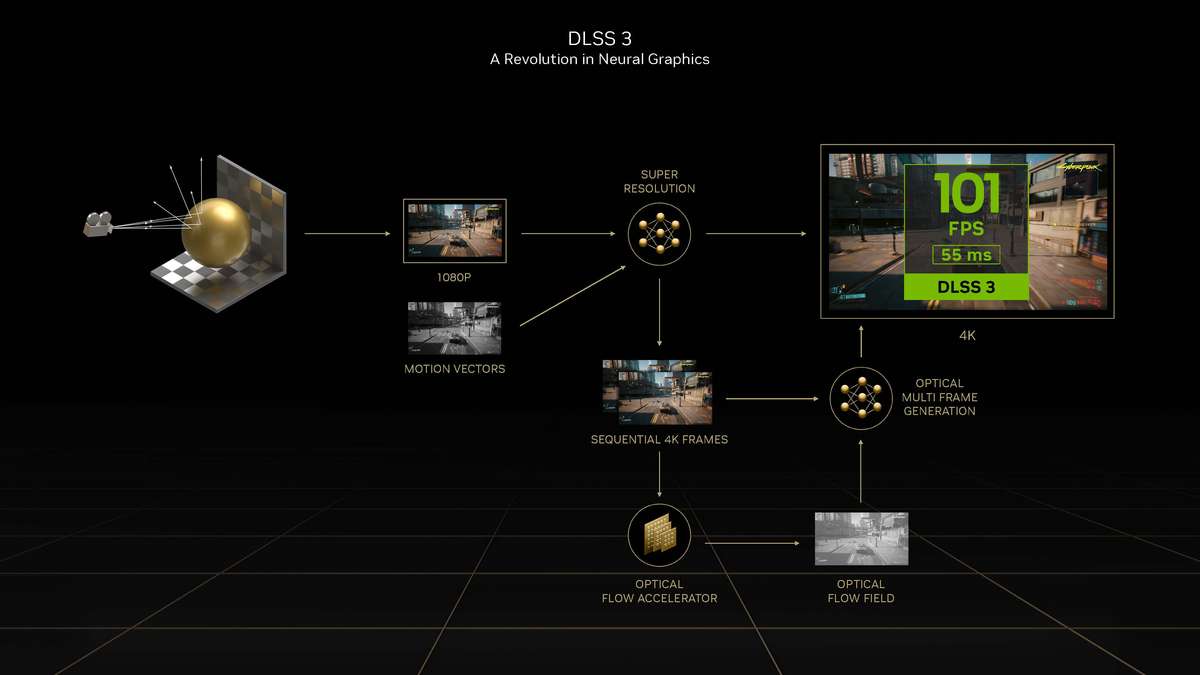
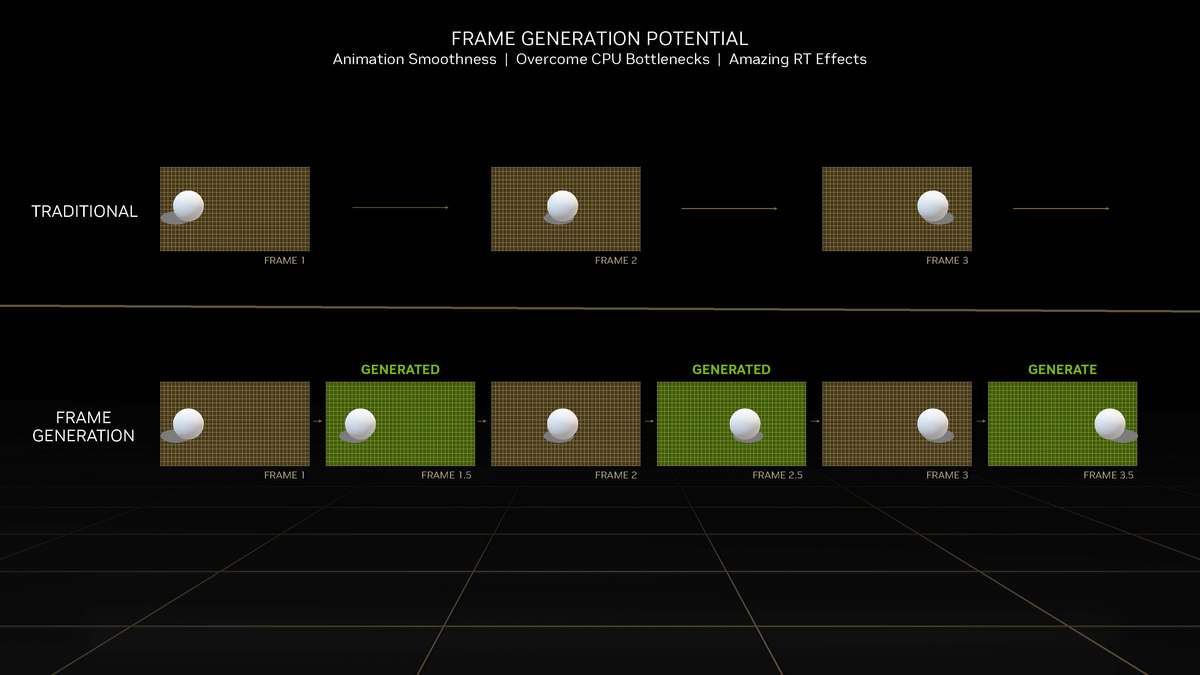
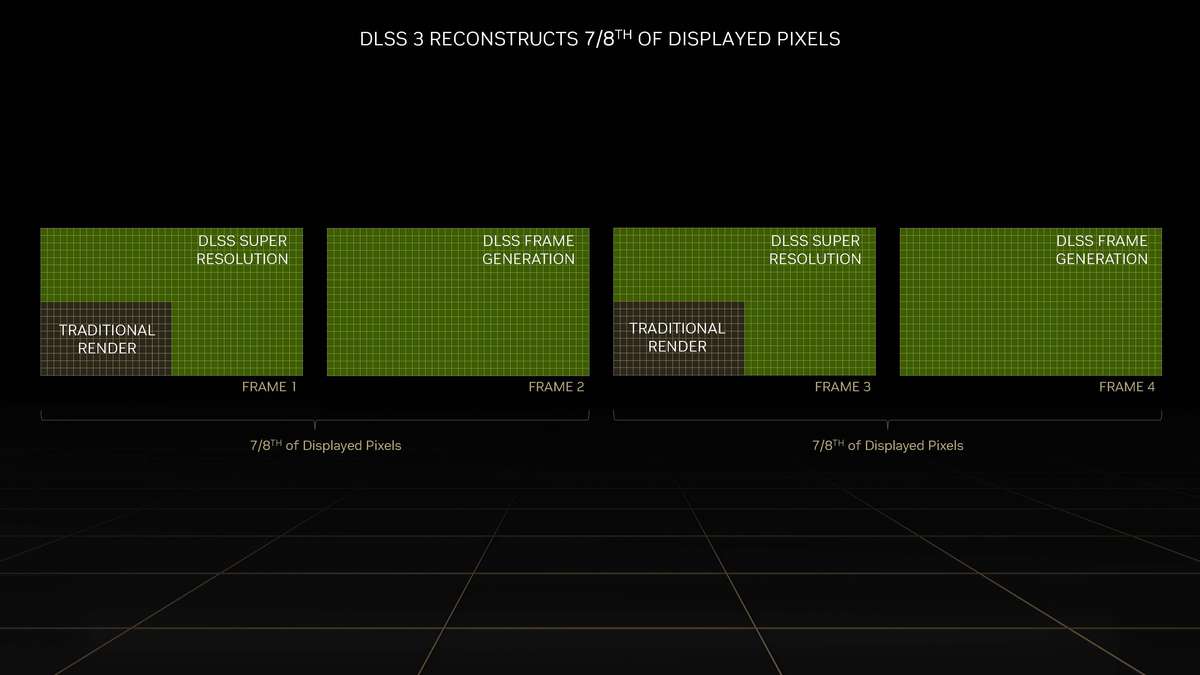
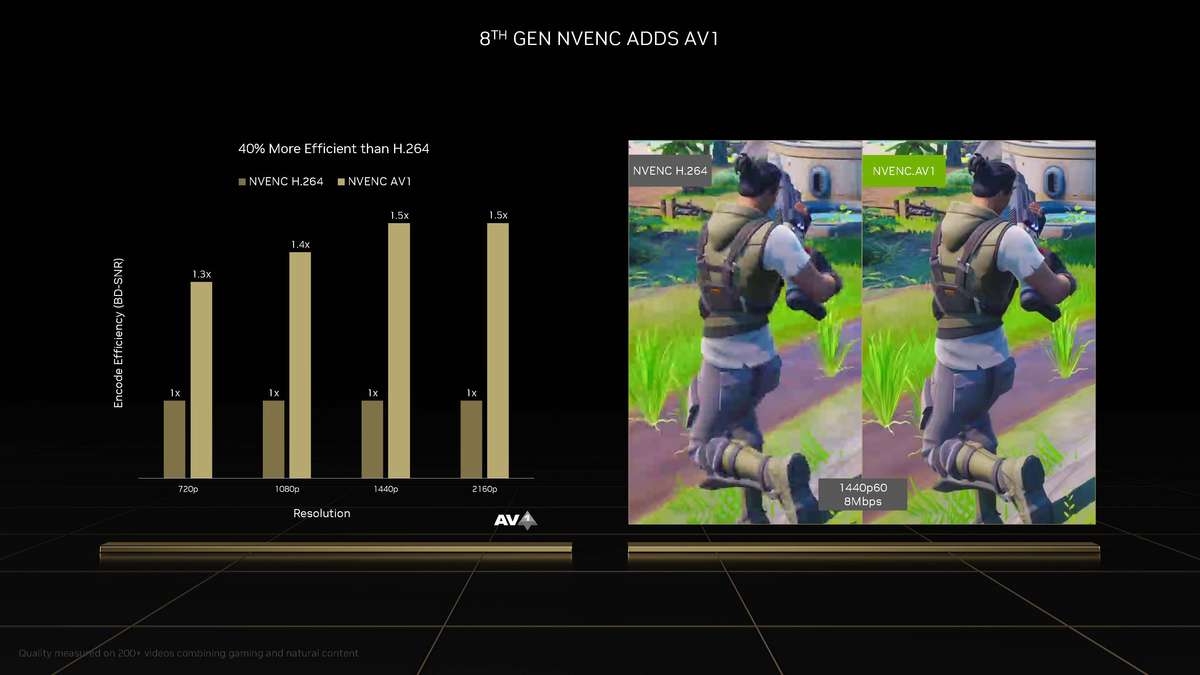
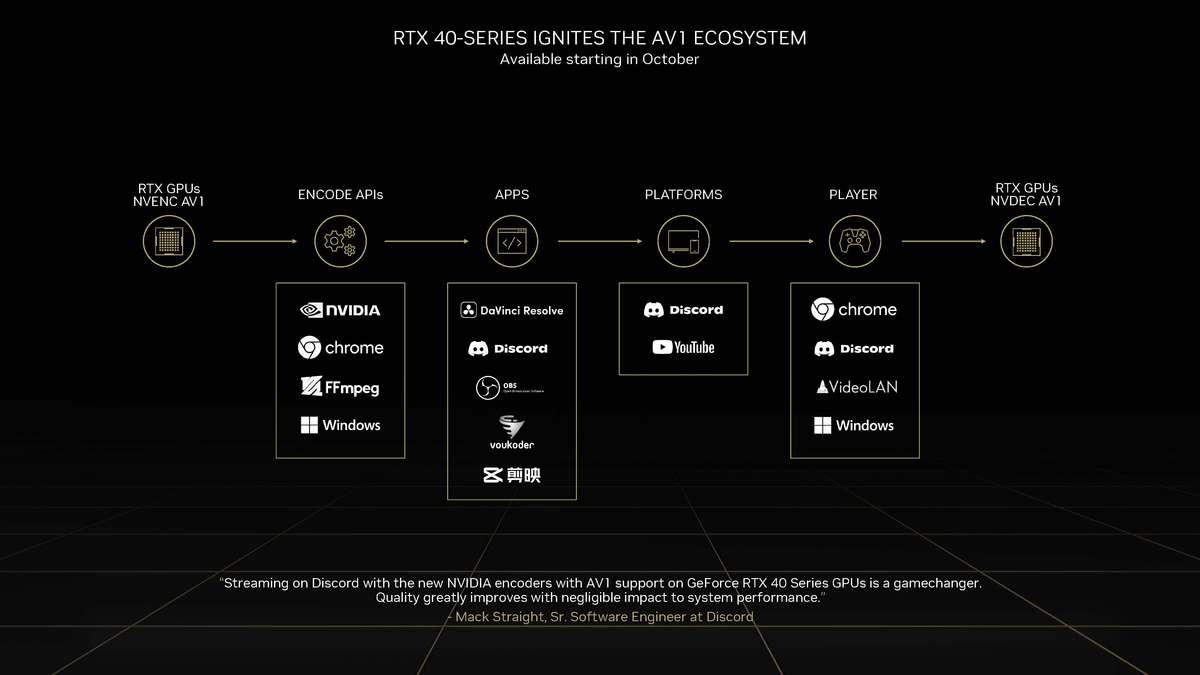
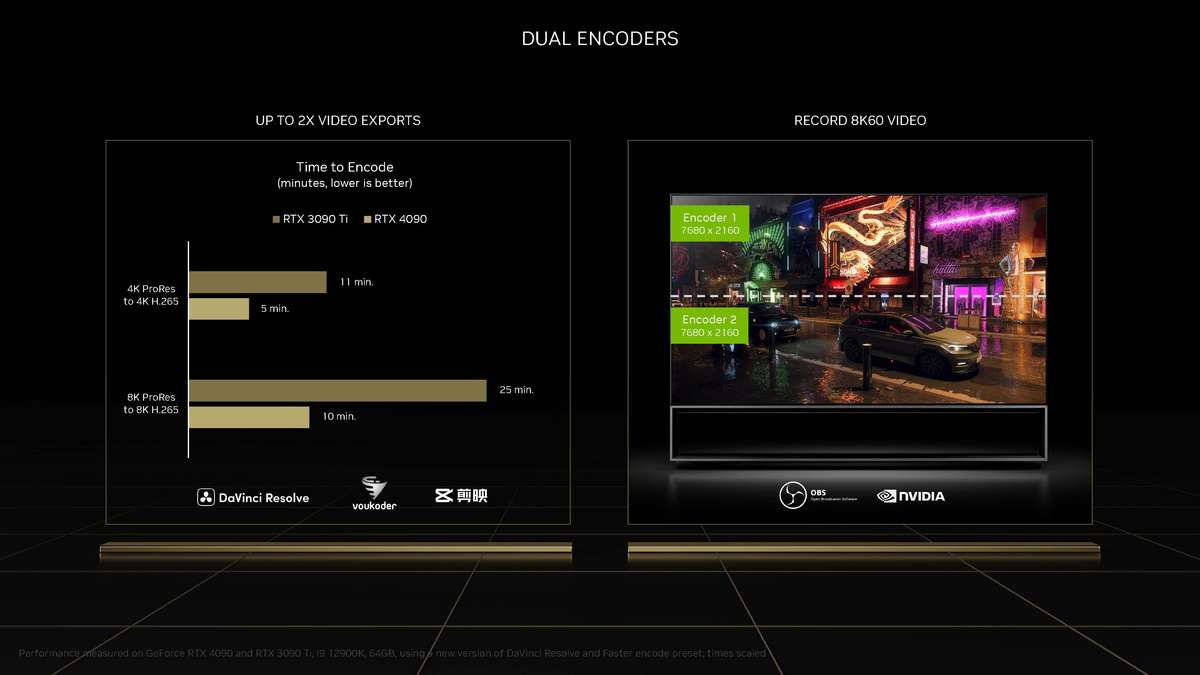
和更高一级的RTX 4080相比,RTX 4070 Ti的SM单元从76组减少至60组,CUDA Cores数量从9728个降低至7680个,Tensor Cores与RT Cores数量也有相应减少,L2缓存从65536KB降至49152KB。相对应的,晶体管数量从459亿个减少到358亿个,因此芯片面积也变小了。 RTX 4070 Ti的显存位宽相比RTX 4080是有所下降,从256bit降至192bit,依然使用GDDR6X显存,不过显存数据速率也从22.4Gbps降低至21Gbps,整体显存带宽从716.8GB/s降至504GB/s,显存容量从16GB减少到12GB。其Boost频率为2610MHz,相比RTX 4080更高,而整卡TGP为285W,比RTX 4080低了35W,推荐电源功率也从750W降低至700W。 Ada Lovelace架构解析SM架构图到了SM单元里面,会发现其整体的结构也是与上一代Ampere架构一模一样,分为四个一样的主要计算模块,一个RT光追核心,以及128KB一级数据缓存/共享内存等。每个主要的计算模块内的结构也和Ampere架构一样,有64KB寄存器文件、零级指令缓存、一个Warp调度器、一个分配单元、16个FP32单精度浮点CUDA核心、16个FP32/INT32单精度浮点和整数混合CUDA核心、一个Tensor Core张量核心、四个载入存储单元、一个特殊功能单元(SFU)用于执行图形差值指令。 差别也很明显,那就是RT Core光追核心从之前的第二代升级到第三代,Tensor Core张量核心也从第三代升级到第四代。 第三代RT Core有效光追算力是上代3倍全新的第三代RT Core可以提供2倍的光线与三角形求交性能,并且加入了两个全新的重要硬件单元,即Opacity Micro-Map引擎和Displaced Micro-Mesh引擎。 Opacity Micro-Map引擎将光线追踪的Alpha-Test几何性能提升2倍;而全新的Displaced Micro-Mesh引擎可动态生成微网格,以产生额外的几何图形。Displaced Micro-Mesh引擎可在提升几何图形丰富度的同时,不以传统复杂几何图形处理的性能和存储成本为代价。 Displaced Micro-Mesh引擎光线追踪的计算是以光线射向一个平面这样的模型来计算的,而实际的渲染中物体几乎不会是简单的平面型,而是各种曲面,所以就需要将曲面分解成许多个小的三角形平面,然后计算光线与三角形求交。在Ampere架构上,面对一个复杂的曲面,如果想得到逼真的光线追踪效果,那么分解的三角形平面是非常多的,多个三角形平面带来非常复杂的BVH,这就非常难以计算。 Ada Lovelace架构的处理方式就不一样,通过Displaced Micro-Mesh引擎,它将这些三角形平面仅通过一个三角形然后加上不同的位移图来表达,显著缩短了BVH的构建时间,同时BVH的存储空间需求也减小了很多,而最终仍然能实现一样的光线追踪最终渲染效果。 实际应用中由于Displaced Micro-Mesh引擎的存在,面对复杂物体的渲染,BVH的构建速度可以超过15倍,而存储空间的需求却可以小20倍之多,越是复杂的物体该引擎的优势就越能体现。 而且Displaced Micro-Mesh引擎不止可以应用在游戏领域,对于创作领域的用户来说,也有软件会支持,目前Adobe、Simplygon这两家企业已经确认得到了支持。 Opacity Micro-Map引擎Opacity Micro-Map引擎则是可以对游戏中常见的树叶这类物体加速光线追踪计算,Ampere架构面对这种场景的Alpha-Test需要多个着色器来进行计算,而Opacity Micro-Map引擎对于这种不透明的对象进行了不透明度的编码,可以更准确的对物体边缘进行光线追踪计算,简化了叶子轮廓之外完全透明和叶子轮廓之内完全不透明的区域的计算,耗费更少的着色器就可以实现真实的光线追踪渲染。 以《传送门》RTX版这个游戏为例,Opacity Micro-Map引擎可以让Gbuffer填充速度加快30%,游戏帧率提高10%。 在这些改进下,第三代RT Core可以使完整的Ada Lovelace架构核心具有200 TFLOPS的有效光线追踪计算能力,几乎是上代产品的三倍。 第四代Tensor核心性能超上代5倍第四代Tensor Core最主要的变化是新增了Hopper FP8 Transformer Engine,可提供1400 TFLOPS的张量处理性能,可以说深度学习性能得到了巨大的飞跃,这也意味着通过它可以实现新的技术想法,后面的DLSS 3我们会再次提到Tensor Core的功劳。 DLSS 3作为这次NVIDIA大力宣传的重点,相信大家都急不可耐想深入的了解这个技术,但是为了更清楚的了解DLSS 3,还要先介绍两个新东西,那就是着色器执行重排序(SER)和Optical Flow Accelerator光流加速器。 着色器执行重排序(SER)提高光追并行效率着色器执行重排序技术的重大作用是可以极大的提升光线追踪性能,这是与CPU的乱序执行一样的重大创新。 由于光线追踪的特性,它很难并行处理,因为光线会向各个方向反射,并与各种类型的表面相交,所以光线追踪的工作负载需要不同的线程处理,需要不同的着色器,并且需要不同的显存来存取中间的计算过程。 GPU的特点就是适合并行处理,只有面对并行处理的任务才可以发挥GPU的特点获得更好的计算效率,而着色器执行重排序就是可以通过实时重新调度任务,即时重新安排着色器负载来提高执行效率,从而更好地利用GPU资源,以实现更佳的光线追踪性能,据称,SER可以为光线追踪带来最高可达3倍的性能提升,整体游戏性能提升可高达25%。 应用了着色器执行重排序(SER)之后,《赛博朋克2077》在全景光线追踪模式下可以提高44%的性能,《传送门》RTX版可以提高29%的性能,《Racer RTX》可以提高20%的性能。 Ada光流加速器算力可超300 TFLOPS回看前面的完整核心图,可以看到左上角清晰的标出了Optical Flow Accelerator,也就是光流加速器,而尽管之前的Ampere架构中没有提及,但同样也是具备的。不同的是,Ada Lovelace架构中大大增加了光流加速器的运算性能,从之前Ampere架构的126 TFLOPS增加到现在的300 TFLOPS(详细值是305 TFLOPS)。 Ada的光流加速器带来的巨大的性能提升,具有更广泛的实用性了,使DLSS 3能够更准确预测场景中的运动,使神经网络能够在保持图像质量的同时提高帧率。前面提到的第四代Tensor Core的1400 TFLOPS的张量处理性能,加上这里Ada Lovelace光流加速器300 TFLOPS的光流运算性能,再加上后方的NVIDIA超级计算机提供的超过1 ExaFLOPS的AI计算性能,这三者就组成了这一代DLSS 3的硬件层面基础。 DLSS 3全方位提升流畅度、延迟和画质新一代的DLSS 3包括全新的帧生成技术、DLSS 2超分辨率技术和NVIDIA Reflex技术,与之对应的游戏中,这三个都启用了才算是完整地开启了DLSS 3。 其中帧生成必须RTX 40系列GPU才能支持,超分辨率则是RTX 40/30/20系列都支持,Reflex的要求最低是GTX 900系列及以后的GPU。总得来说,DLSS 3是提升游戏体验的一整套解决方案,也就是说对于游戏体验的三要素:流畅度、延迟和画质。DLSS 3是全方位的提升,而不是以拆东墙补西墙的方式。 DLSS 3的帧率之前的DLSS 2,提升帧率的方式简单说就是以低分辨率渲染,然后通过AI训练重建高分辨率画面返回输出,比如我们将游戏设置成4K,打开DLSS,那么实际的计算过程是先以1080p分辨率渲染帧画面,然后AI学习经过训练的更高分辨率的帧再将这个帧画面压缩到4K最终输出,中间相差的这3/4部分的像素信息是通过AI计算来添加的(本地主要是Tensor Core来计算)。由于以低分辨率渲染,所以在AI补充像素的性能足够的情况下,帧率自然可以提高了。 这样的方式无法突破CPU性能的瓶颈,毕竟降低原始渲染分辨率可以使得GPU每一帧的计算量更少,但是CPU每一帧的计算量是不变化的(因为CPU负责计算的部分与分辨率并无关系)。实际上,由于帧率提高,最终CPU的计算量还增大了。 那么DLSS 3是怎么做的呢? 首先,还是与DLSS 2一样,比如输出4K游戏画面的话,它也是先降低原始渲染分辨率到1080p,然后通过AI计算来添加像素再压缩成4K画面。在连续的游戏画面中,我们就可以通过这样得到连续的4K帧画面,第1帧、第2帧、第3帧等等。 然后这样的每两帧之间,DLSS 3通过光流加速器为神经网络提供像素级的帧到帧的运动方向和速度信息,然后通过分析前一帧和当前帧几何图形和像素的运动矢量并将其输入至神经网络,就能计算出两帧中间的帧画面了。 实现超越CPU限制的帧数这样连续下去的话,原本的第1帧、第2帧、第3帧中间都会有一个新的帧,等于实际最终输出的帧画面中,有1/2是没有CPU参与的,完全是GPU计算出来的,所以理论上可以将原本受限于CPU性能的游戏帧率提高一倍。 另外,我们去关注像素的话,会发现靠传统渲染方式计算的像素其实只有1/8,最终输出的游戏画面7/8的像素其实都是通过DLSS 3的一系列AI计算填补上的,这极大的提升了效率。 DLSS 3的画质其实看我们的网站的网友评论可以看到,还是有很多网友对DLSS技术很抗拒,认为不是原始渲染出的画面就不好,或许这一观念是时候需要改变了。且不说网友有这一观念可能是由于初代DLSS技术确实效果不佳,形成了刻板印象,即便之后的DLSS 2超分辨率技术已经有很好的画面也很难摒弃已经形成的观念,对于现在的DLSS技术其实可以比较一下这几帧画面,已经完全看不出区别。 对于DLSS 3的生成帧这方面大家不免想到已经问世好久的各种插帧技术,DLSS 3的生成帧确实也可以算作插帧的一种,但是又与其他的插帧技术完全不一样。 简单的插帧技术利用两帧之间像素的位移来确定中间帧的图像,这样其实非常容易出现明显令人觉得视觉异常的画面,特别是对于阴影这种需要计算的画面效果,当主体移动之后,正确的阴影是需要经过复杂计算的,单单根据像素的位移来确定的画面几乎肯定违反客观世界的物理规律。 DLSS 3使用光流加速器分析两帧连续的游戏图像,计算帧到帧之间物体、元素的运动矢量数据,综合游戏中的一对超级分辨率帧,以及引擎和光流运动矢量,并将其输入至卷积神经网络,计算生成出新的一帧,大大提高了画面的准确性。 DLSS 3的延迟通过前面的梳理大家会发现DLSS 3尽管提高了帧速率,也保证了画质,但是对于延迟是没有缩短的,因为每一个新生成的帧都是需要后一帧渲染出来之后才可以准确生成的。更高的帧率提升了游戏的顺滑程度,但延迟会影响游戏的响应度,如果延迟太高,游戏的体验也不会好,而为此,DLSS 3也集成了NVIDIA Reflex技术来降低延迟提高响应速度。 总得来说,DLSS 3是包括了基于AI的超分辨率提升技术、基于AI的帧生成技术以及NVIDIA Reflex低延迟技术这些软件层面以及第四代Tensor Core的1400 TFLOPS的张量处理性能、Ada Lovelace光流加速器300 TFLOPS的光流运算性能以及NVIDIA超级计算机提供的超过1 ExaFLOPS的AI计算性能组成的硬件层面综合实现的一项新技术,对于游戏体验的提升也不是单方面的,而是全方位的提升。 全新第八代NVENC支持AV1编码和双编码器Ada Lovelace架构相比Ampere架构的另一项重要升级就是NVIDIA 编码器 (NVENC)升级到了第八代,开始支持AV1编码了。AV1的效率比H.264高40%,这意味着在传输同样质量的画面时候只需要大约70%的数据量,或者说在同样的带宽下可以实现更清晰的画面质量,并且由于AV1是免费、开放的,可以让厂商节省相当一笔费用,AV1已经明显将要取代H.264成为主流格式。 在中国的备受欢迎的视频编辑应用“剪映专业版”、Blackmagic Design 的 DaVinci Resolve 18、以及 Adobe Premiere Pro 较为流行的 Voukoder 插件均支持 AV1,且均可通过编码预设使用NVENC AV1编码器。此外,OBS、Discord以及更多的公司都已在采用NVENC AV1编码器。 比如首发的RTX 4090给开放了两个NVENC编码器,这两个NVENC可实现协同工作,并自动分配以实现双路输出。全新的双编码器可将视频导出时间缩短至原来的一半,未来主播用户可借助第八代编码器中AV1双编码器的优势提升直播体验,还可以通过OBS Studio录制高达8K@60FPS的内容。
| 


 雷达卡
雷达卡
 发表于 2023-2-20 00:13
发表于 2023-2-20 00:13

















 照妖镜
照妖镜
