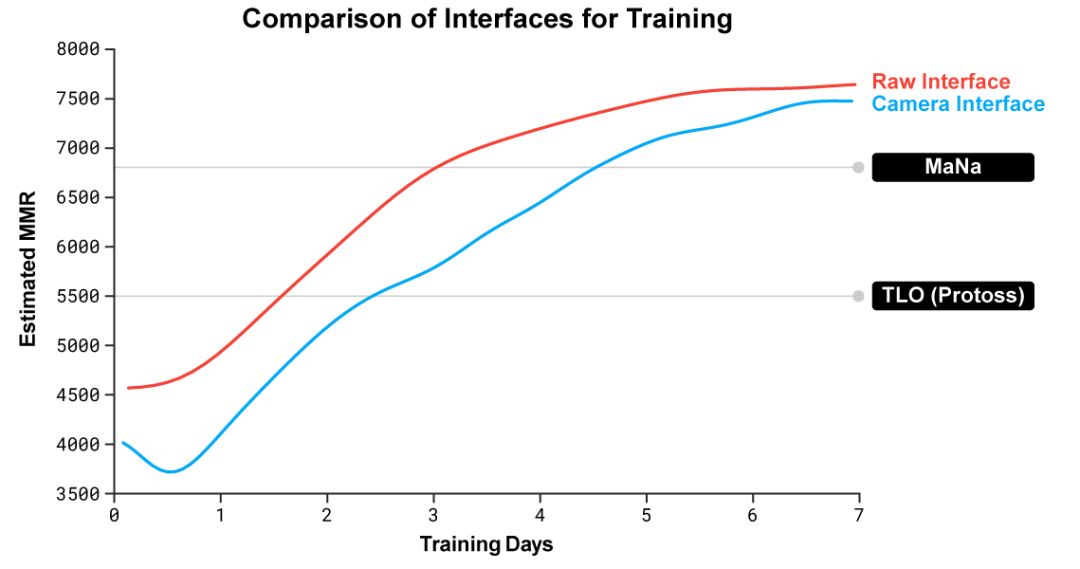
星际争霸 星际争霸是由暴雪娱乐公司开发的一款经典即时战略游戏。与国际象棋、Atari游戏、围棋不同,星际争霸具有以下几个难点: 1、 博弈——星际争霸具有丰富的策略博弈过程,没有单一的最佳策略。因此,智能体需要不断的探索,并根据实际情况谨慎选择对局策略。 2、 非完全信息——战争迷雾和镜头限制使玩家不能实时掌握全场局面信息和迷雾中的对手策略。 3、 长期规划——与国际象棋和围棋等不同,星际争霸的因果关系并不是实时的,早期不起眼的失误可能会在关键时刻暴露。 4、 实时决策——星际争霸的玩家随着时间的推移不断的根据实时情况进行决策动作。 5、 巨大动作空间——必须实时控制不同区域下的数十个单元和建筑物,并且可以组成数百个不同的操作集合。因此由小决策形成的可能组合动作空间巨大。 6、 三种不同种族——不同的种族的宏机制对智能体的泛化能力提出挑战。 图3. 直播中组织者分析Atari,围棋,星际三者在信息获取程度、玩家数量、动作空间、动作次数的不同,难度呈现逐渐提升 正因为这些困难与未知因素,星际争霸不仅成为风靡世界的电子竞技,也同时是对人工智能巨大的挑战。 评估AlphaStar战力 星际争霸中包含神族、人族、虫族三种选择,不同种族有不同的作战单位、生产机制和科技机制,因而各个种族间存在战术制衡。为了降低任务训练所需时间,并避免不同种族间客观存在的不平衡性,AlphaStar以神族对阵神族为特定训练场景,固定使用天梯地图-CatalystLE为训练和对决地图。 面对虫族职业玩家TLO和排名更加靠前的神族职业玩家MaNa的轮番挑战,AlphaStar凭借近乎无解的追猎微观操作和凤凰技能单位的配合,能在绝大多数人类玩家都认为严重受到克制的兵种不朽下,在正面战场上反败为胜扭转战局,并最终兵不血刃的横扫人类职业玩家,取得了星际争霸AI当前最佳的表现水平,在实时战略游戏上取得了里程碑式的意义。 图4. 追猎者相互克制兵种关系 AlphaStar是如何训练的? AlphaStar的行为是由一个深度神经网络产生。网络的输入来自游戏原始的接口数据,包括单位以及它们的属性,输出则是一组指令,这些指令构成了游戏的可行动作。网络的具体结构包括处理单位信息的变换器(transformer),深度LSTM核(deep LSTM core),基于指针网络(pointer network)的自动回归策略头(auto-regressive policy head),和一个集中式价值评估基准(centralised value baseline)。这些组成元件是目前最先进的人工智能方法之一。DeepMind将这些技术组合在一起,有信心为机器学习领域中普遍存在的一些问题,包括长期序列建模、大规模输出空间如翻译、语言建模、视觉表示等,提供一种通用的结构。 AlphaStar权重的训练同样是使用新型的多智能体学习算法。研究者首先是使用暴雪发布的人类匿名对战数据,对网络权重进行监督训练,通过模仿来学习星际天梯上人类玩家的微观、宏观策略。这种模拟人类玩家的方式让初始的智能体能够以95%的胜率打败星际内置电脑AI精英模式(相当于人类玩家黄金级别水平)。 在这初始化之后,DeepMind使用了一种全新的思路进一步提升智能体的水平。星际本身是一种不完全信息的博弈问题,策略空间非常巨大,几乎不可能像围棋那样通过树搜索的方式确定一种或几种胜率最大的下棋方式。一种星际策略总是会被别一种策略克制,关键是如何找到最接近纳什均衡的智能体。为此,DeepMind设计了一种智能体联盟(league)的概念,将初始化后每一代训练的智能体都放到这个联盟中。新一代的智能体需要要和整个联盟中的其它智能体相互对抗,通过强化学习训练新智能体的网络权重。这样智能体在训练过程中会持续不断地探索策略空间中各种可能的作战策略,同时也不会将过去已经学到的策略遗忘掉。 | 



 雷达卡
雷达卡














 发表于 2019-1-28 00:31
发表于 2019-1-28 00:31




 照妖镜
照妖镜 楼主
楼主